How Voice Assistants Are Changing Human Computer Interaction

Voice assistants aren't just a convenience they're rewriting how we interact with machines. Over the last decade, smart assistants have moved from novelty to essential. Whether it's asking Siri for directions, telling Alexa to play a podcast, or using a custom enterprise bot to handle customer queries, voice interfaces are shifting expectations about usability, accessibility, and the role AI plays in everyday life.
In this post I’ll you walk through how voice assistants are reshaping human computer interaction (HCI). I'll cover the tech under the hood, practical UX patterns, pitfalls teams commonly hit, and what the future of voice interfaces looks like. I’ve noticed that people from product managers to UX designers often underestimate the interplay between language, context, and system constraints so I'll add concrete tips you can use when building voice- and AI-driven products.
Why voice matters: the promise of conversational AI
Voice turns typing and tapping into conversation. That simple shift has three big implications:
- Lower friction. You don't need hands or eyes to interact. That's huge for driving, cooking, or accessibility contexts.
- Natural expression. People can speak in full sentences, use interruptions, or ask follow-ups. Conversational AI tries to map that fluidity into software behavior.
- Ambient integration. Voice works in the background smart assistants can be woven into routines, appliances, and workflows without demanding full attention.
I've seen this play out in healthcare and customer support projects: by adding a voice channel we remove barriers for users who struggle with complex menus or small screens. That isn't just convenience it expands who can use the system reliably.
How voice assistants actually work (a quick tour)

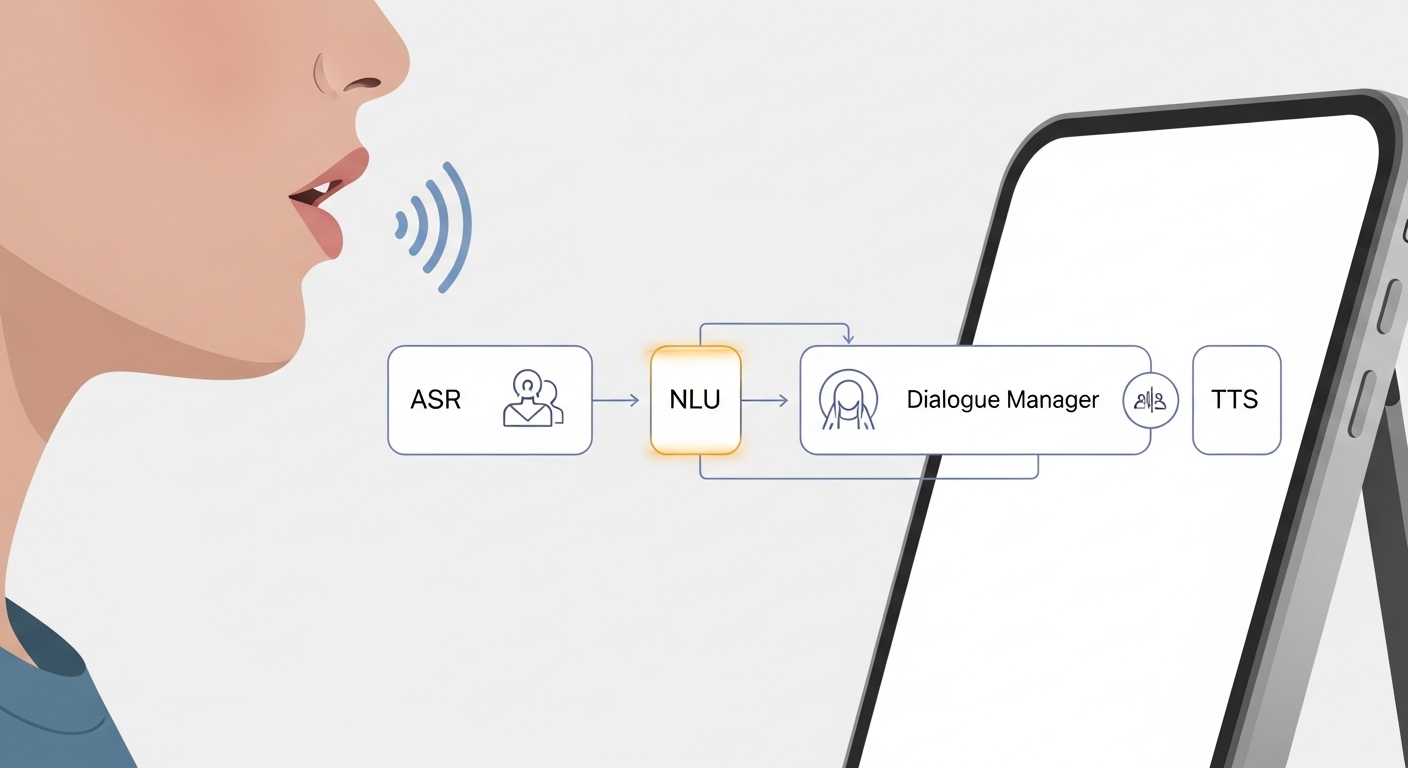
Under the hood, most modern voice systems pipeline a handful of components:
- Automatic Speech Recognition (ASR) converts audio to text.
- Natural Language Understanding (NLU) extracts intents and entities from that text.
- Dialogue Manager decides the next action answer, follow-up question, or handoff.
- Text-to-Speech (TTS) turns responses back into voice.
These layers lean on machine learning. ASR now uses deep acoustic models; NLU combines transformers and intent classifiers; dialogue systems use state machines or neural policies. Cloud services (AWS, Google Cloud, Microsoft, and specialized vendors) host the heavy lifting, but we’re also seeing on-device models for privacy and latency-sensitive use cases.
One practical detail teams often miss is latency. If your assistant takes more than a second to reply, users notice. That delay breaks conversational flow. So the engineering trade-off between model accuracy and response time matters. In my experience, optimizing for perceived speed (progressive replies, audible cues) can be more effective than shaving milliseconds off model inference alone.
From commands to conversation: evolution of voice UX
Early smart assistants were command-driven. You said "Turn on the light" and the system did it. Pretty predictable. Today’s conversational AI handles multi-turn interactions and context. That’s a big leap and a much harder design problem.
Here’s what that means in practice:
- Context retention: Systems now remember prior turns “Dim the living room lights. Set them to 50%.” The assistant needs to resolve “them.”
- Implicit commands: Users assume the assistant understands less explicit language. “I’ve got guests coming” could trigger a lighting or thermostat scene if you build that mapping.
- Personalization: Conversational assistants can learn preferences, but that brings privacy and predictability trade-offs.
Designers must think like conversational partners. That includes handling interruptions, partial answers, and natural phrasing not just rigid command grammars. From a UX standpoint, you're designing a persona as much as a feature set.
Design principles for voice-first UX (what works)
When product teams approach voice design, these principles consistently improve outcomes:
- Be discoverable. Voice is invisible unless users know what to ask. Offer hints, examples, and fallbacks that suggest behavior without overwhelming them.
- Limit cognitive load. Short responses win. Don’t read a ten-point list; offer highlights and say “Would you like more details?”
- Guide users with affordances. Use confirmations and preview actions: “Okay, I’ll set your thermostat to 72. Want me to save this as your evening setting?”
- Design for failure. Expect ASR/NLU errors. Provide graceful recovery: paraphrase what you heard, ask a clarifying question, or offer quick alternative actions.
- Respect privacy. Give users control over data, voice history, and personalization. Transparency builds trust.
One common mistake: treating voice like text. People phrase things differently when speaking. They use fillers, pauses, and colloquialisms. If you design intents only for clean text input, you'll miss real-world usage. Add test data that includes false starts, slang, and noisy transcripts.
Siri vs Alexa vs Google Assistant: pros, cons, and ecosystems
Comparing mainstream assistants helps clarify platform choices. I like to frame this as a trade-off between reach, control, and integration complexity.
- Siri is tightly integrated into Apple's ecosystem. If you're building for iOS users and want native privacy features, it's a strong option. However, third-party integration is more limited compared to others.
- Alexa dominates smart-home integrations. It’s flexible for custom skills and hardware makers. Alexa’s developer tools are mature, but Alexa skills still require careful voice UX design to avoid poor user experiences.
- Google Assistant offers strong NLU and search integration. It’s particularly good at follow-up questions and handling open-ended queries due to Google’s search stack.
Which should you pick? If your product depends on deep system access (sensors, native apps), platform choice matters. If you want wide reach, Alexa and Google cover lots of devices; Siri hits highly engaged Apple users. For enterprise or bespoke products, building a custom assistant (or using a vendor) often makes more sense you control data, intent models, and brand voice.
Industry applications: where voice is making a difference
Voice assistants are no longer confined to smartphones and speakers. Here are real-world areas where they’re reshaping HCI:
- Healthcare. Clinicians use voice to capture notes, navigate records, and retrieve vital info hands-free. That saves time, but accuracy and privacy are crucial.
- Automotive. Voice reduces driver distraction and supports navigation, infotainment, and vehicle diagnostics. Latency, offline features, and noise robustness are key engineering concerns.
- Customer service. Conversational AI handles routine inquiries, routes complex cases to humans, and automates ticketing. Good handoff design prevents frustration.
- Retail and e-commerce. Voice shopping and discovery are emerging. Designing for smaller screens (or none at all) forces clearer, more concise interactions.
- Industrial and field work. Technicians use voice to access manuals, log issues, and perform checks while keeping hands free.
In each case, domain knowledge matters. An out-of-the-box assistant rarely nails industry-specific terminology or workflows. If you’re building for a niche, invest in custom vocabularies, tailored NLU models, and realistic testing data.
Privacy, security, and ethical considerations
Voice interfaces raise unique privacy concerns. Your microphone listens for wake words. Audio data can be sensitive. So teams must design for consent and transparent data practices.
Key considerations:
- Data minimization: Only store what you need. Transient storage reduces risk.
- Local processing: When possible, keep ASR or hotword detection on the device to limit cloud exposure.
- Voice spoofing: Voice biometrics aren't foolproof. Combine factors (device token, behavior) for critical actions like payments.
- Bias and fairness: ASR can have higher error rates for accents or dialects. Test across demographic groups early and often.
Regulation is catching up. GDPR, CCPA, and other rules affect how you store and process voice data. In my experience, building opt-in features and clear privacy UIs not only complies with regulations, it also builds user trust which matters more for long-term adoption than any short-term data capture.
Multimodal interfaces: not voice-only, but voice-first
Voice doesn't replace screens it complements them. The real power comes from multimodal experiences that combine speech, touch, gesture, and visuals. Consider these patterns:
- Voice + screen: Use voice for input and quick responses, and screens for rich content like maps, receipts, or charts.
- Voice + gestures: In AR/VR and automotive, gesture combined with voice reduces ambiguity (e.g., “that one” while pointing).
- Progressive disclosure: Start with a short vocal answer, and offer to display or send more detailed information to the user's device.
For product teams, this means designing conversations that anticipate visual follow-ups and handoffs. If the user says “Show me my recent orders,” the assistant can respond vocally and push a list to the app. That kind of orchestration feels cohesive and respects different contexts like walking vs sitting at a desk.
Measuring success: metrics that matter for voice
To know if your voice assistant is working, track both technical and human-centered metrics:
- Intent recognition accuracy. How often does the system correctly map utterances to the right intent?
- Task completion rate. Are users able to finish tasks without human help?
- Latency. Time to first meaningful response affects perceived conversationality.
- User satisfaction (CSAT/NPS). Do users like the interaction? Surveys after sessions work well.
- Fallbacks and handoffs. Rate of fallback to generic responses or human agents.
- Retention and frequency. Do users return to the voice channel, and how often?
One qualitative metric I recommend is "friction points per session" log where users get stuck, repeat commands, or ask the same clarification. Those hotspots are the lowest-hanging fruit for improvements.
Common implementation pitfalls (and how to avoid them)
I've worked with teams that underestimated the complexity of voice projects. Here are the mistakes that come up most often, and practical fixes.
- Assuming text UX will translate to voice. Fix: Build separate conversational flows and test with real spoken input.
- Ignoring ambient noise and ASR errors. Fix: Test in real environments, tune wake-word sensitivity, and add noise-robust models.
- Overloading conversations with info. Fix: Break answers into digestible chunks and offer follow-ups.
- Not designing for graceful failure. Fix: Add confirmations, paraphrasing, and easy fallbacks to menu options.
- Skipping privacy-first design. Fix: Implement opt-ins, clear data policies, and local processing where feasible.
Another frequent blind spot is the long tail of intents. Teams often train models on a few common phrases and ignore the varied ways real users will ask. Invest in long-tail data and active learning pipelines to capture real usage patterns as the system runs.
Practical roadmap: how to add voice to your product
If you’re a product manager or founder wondering where to start, here’s a pragmatic sequence I’ve used with teams:
- Define the core tasks. Start small. Pick one or two high-value tasks that benefit from hands-free or conversational interfaces.
- Prototype quickly. Use no-code or low-code voice prototyping tools to test flows with users. You can validate UX without perfect ASR.
- Measure and iterate. Run controlled experiments, capture transcripts, and refine intent models.
- Decide build vs buy. Evaluate platform trade-offs: do you use mainstream assistants, a cloud provider, or a specialized vendor?
- Scale thoughtfully. Add personalization and extra features only after your base metrics stabilize.
For startups, I often recommend integrating voice as an augmentation, not the core product, until you know the interaction pattern works. Keep your MVP narrow: handle one language well, test in a controlled acoustic environment, and expand from there.
The role of data and continuous improvement
Voice systems benefit massively from real user data but only if you handle it wisely. Continuous improvement means collecting transcripts (with consent), labeling edge cases, and retraining models.
Practical suggestions:
- Keep a human-in-the-loop review pipeline for low-confidence utterances.
- Use active learning to surface ambiguous examples for labeling.
- Maintain a taxonomy of intents and entities so you can evolve your NLU reliably.
- Track per-intent accuracy and prioritize fixes based on task importance.
Don't forget to anonymize and minimize PII. In regulated industries like healthcare, invest in on-prem or private cloud options that let you control the data lifecycle.
Emerging trends: where voice interfaces are heading
Voice tech keeps evolving quickly. Here are trends I’m watching (and building towards):
- On-device models: Smaller, efficient models mean privacy and offline capability. This is crucial for cars and healthcare devices.
- Few-shot and zero-shot learning: Newer NLU models generalize better with less data, which helps with scarce vertical vocabularies.
- Emotion-aware assistants: Detecting sentiment and adjusting tone can improve support experiences, but it's tricky and raises ethics questions.
- Multimodal composability: Systems will fluidly combine voice, vision, and gesture to create richer experiences.
- Voice as a platform: Brands will invest in proprietary voice experiences to own customer touchpoints, similar to apps and web presence today.
I'm particularly excited about on-device language models for low-latency, private assistants. That changes the calculus for many product teams: you can deliver conversational AI without routing everything to the cloud.
Real-world example: a small case study
At one project I consulted on, the team integrated a voice assistant into a field-service app. Techs needed hands-free access to installation guides and to log findings while working.
We started with a focused scope: three voice commands (retrieve manual, log issue, set status). After prototyping, we learned the most common failure was misrecognizing shorthand phrases used by technicians. We solved that by adding custom vocabularies and onboarding training phrases, and by offering quick visual confirmations on the tablet.
Within two months, task completion rate rose 28% for the targeted workflows, and technicians reported fewer interruptions. The key lesson? Narrow scope, real-world audio, and domain-specific language were decisive.
Hiring and team structure tips
Building voice assistants blends skills from UX, ML, and software engineering. Here’s an effective setup I’ve seen work:
- Conversation Designer: Focus on dialog flows and microcopy.
- NL Engineer: Handles intent/entity modeling, training pipelines, and evaluation.
- Frontend/Embedded Engineer: Integrates the assistant into devices or apps and manages latency and audio capture.
- Data Ops/Labeling: Manages transcript pipelines, labeling workflows, and quality control.
- Product Manager: Ties metrics to business outcomes and prioritizes the roadmap.
Cross-functional pairing a conversation designer with an NL engineer speeds up iteration. If you can, bring in domain experts during early prototyping to seed your vocabulary and edge cases.
Also read:-
- Top 7 Benefits of Hybrid AI + Human Support for SMBs
- Top 10 Ways AI Chatbots Enhance Customer Support Efficiency
- How AI Virtual Assistants Are Revolutionizing SMB Operations
Common questions from teams starting out
Here are short answers to recurring questions I hear:
- Should we build our own assistant or use Alexa/Google/Siri? If you need custom domain reasoning, data control, or a branded voice, consider building or using a specialist vendor. For broad reach and quick integrations, leverage platform assistants.
- How do we handle accents and dialects? Collect diverse training data and test with representative users. Off-the-shelf ASR often underperforms on certain accents; plan for tuning.
- How much audio should we store? Store minimal context needed for improvement and for debugging. Always get consent and provide clear opt-out options.
- How do we make voice discoverable? Combine in-app prompts, onboarding tutorials, and contextual affordances (e.g., a mic icon or suggested phrases).
Wrapping up: the future is conversational, but design still wins
Voice assistants are changing human–computer interaction by making systems more conversational, ambient, and accessible. But technology alone doesn't create great experiences. The teams that succeed are those who pair strong conversational design with engineering that accounts for latency, noise, privacy, and long-tail language.
In my experience, the projects that scale are the ones that start small, measure obsessively, and invest in real-world testing. If you're a product leader, focus on high-value tasks and build a data-backed roadmap. If you're a UX designer, prototype with spoken input early. And if you're an AI researcher or engineer, prioritize models that handle variability and degrade gracefully when they fail.
Why Agentia.support
At Agentia.support we help companies design and deploy AI voice technology that actually works in the real world. We combine conversational design, robust natural language processing, and practical deployment strategies so your assistant delivers measurable results. Whether you're evaluating Siri vs Alexa or building a custom voice agent for a vertical use case, we can help bridge the gap between research and production.
If you want to discuss how voice can improve your product or workflow, we’d love to help. We work with startups and enterprises to prototype, build, and scale voice-first experiences while keeping privacy and business metrics front-and-center.
Helpful Links & Next Steps
Frequently Asked Questions (FAQ)
1. What are voice assistants?
Voice assistants are AI-powered tools like Siri, Alexa, and Google Assistant that understand spoken language and perform tasks or provide information.
2. How are voice assistants changing human–computer interaction?
They make interactions conversational, hands-free, and ambient, reducing friction, improving accessibility, and enabling natural communication with devices.
3. How do voice assistants work?
They use Automatic Speech Recognition (ASR) to convert speech to text, Natural Language Understanding (NLU) to detect intent, Dialogue Management to decide actions, and Text-to-Speech (TTS) to respond.
4. What are key design principles for voice UX?
Focus on discoverability, short responses, guiding users with affordances, handling errors gracefully, and respecting privacy and personalization.
5. Should I use Siri, Alexa, Google Assistant, or build a custom assistant?
Use Siri for iOS apps, Alexa for smart-home integrations, Google Assistant for strong NLU and search, or build a custom assistant for domain-specific intelligence and branded experiences.
6. Which industries benefit most from voice assistants?
Healthcare, automotive, customer service, retail/e-commerce, and industrial/field work benefit from hands-free, efficient interactions.
7. How do I measure the success of a voice assistant?
Track metrics like intent recognition accuracy, task completion rates, latency, user satisfaction, fallback rates, and retention.
8. What are common pitfalls in implementing voice assistants?
Assuming text UX works for voice, ignoring noise, overloading conversations, neglecting privacy, and not handling long-tail phrases or edge cases.